Which has more structure—data or information? The answer might not be as straightforward as it seems.
In the world of data and information management, the terms “structured” and “unstructured” are frequently thrown around. But what if their meanings aren’t as fixed as they seem? Depending on context, what is structured in one domain might appear unstructured in another. This paradox is both fascinating and pivotal to understanding how we manage and extract value from data in an increasingly digital world.
To visualize this paradox, consider the accompanying diagram:
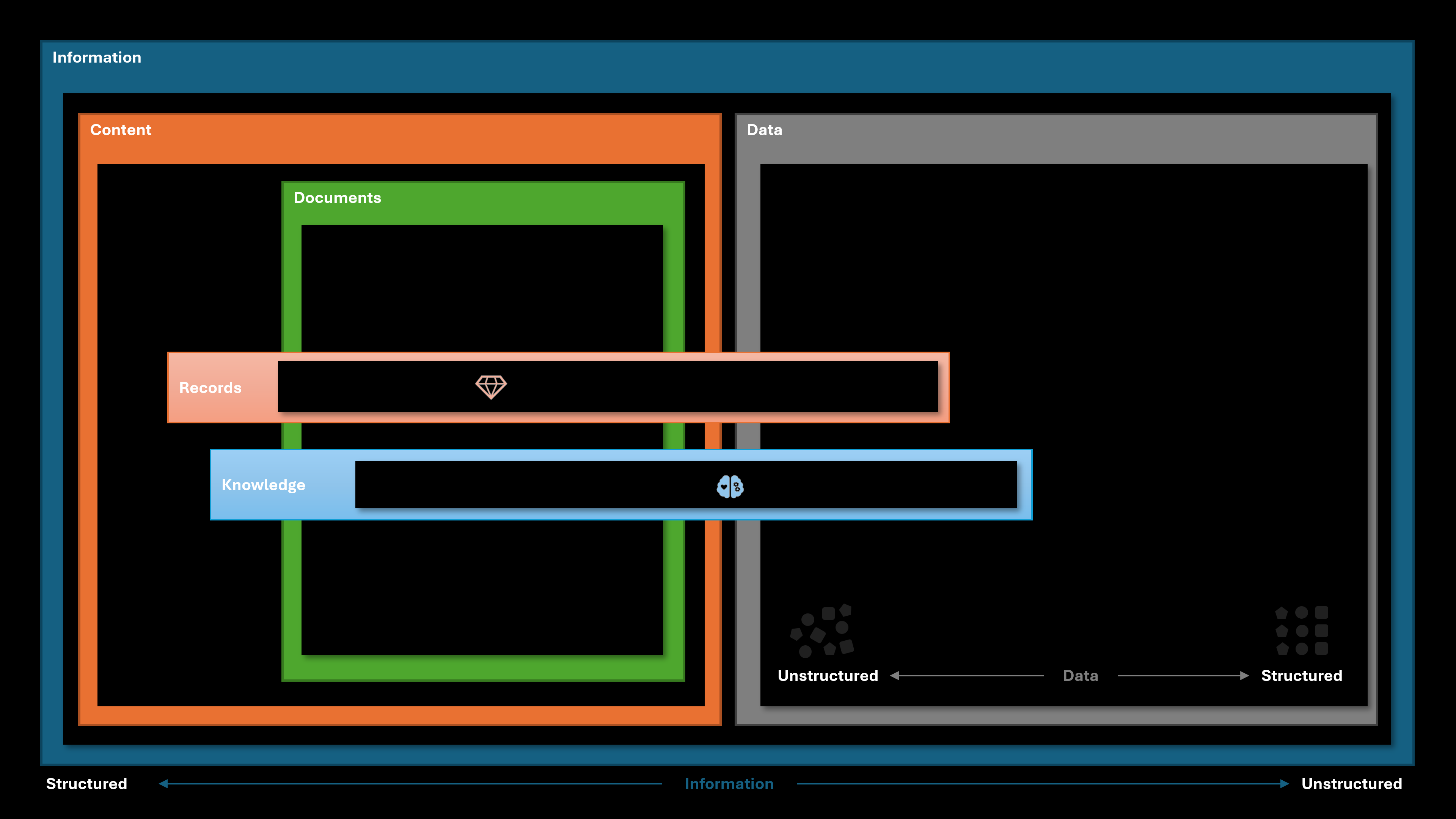
Explaining the Diagram
This diagram highlights the dynamic relationship between data, content, and information, with information (blue) forming the overarching framework that includes everything. Information provides the context and meaning derived from both data and content.
- Data (Right Side, Grey): Data begins raw and unstructured, like a jumble of numbers or text. As it gets organized (e.g., into databases or spreadsheets), it becomes more structured and useful for specific tasks.
- Content (Left Side, Orange): Content serves as the bridge between raw data and structured information narratives. It includes documents, presentations, and other materials designed to communicate meaning.
- Documents (Inside Content): These are specific forms of content that are often structured and tailored for particular purposes, like reports or manuals.
Two key elements cross both data and content:
- Records (Peach): These are authoritative pieces of information that maintain both structure (e.g., metadata, timestamps) and traceability, straddling the line between raw data and organized content.
- Knowledge (Light Blue): Knowledge represents insights derived from both data and content. While often unstructured and reliant on human expertise, it gains structure through tools like knowledge graphs and collaborative platforms.
The horizontal axis shows the continuum from structured to unstructured, while the vertical axis reflects the progression from raw data to meaningful information. By understanding this interplay, we see how all these elements exist within and depend on the overarching context of information, which encompasses the entire framework.
Understanding Structured and Unstructured Data
Structured Data is highly organized and easily searchable. Imagine rows and columns in a spreadsheet or tables in a database. Examples include:
- Customer information in a CRM system.
- Financial transactions in a ledger.
- Inventory records in a database.
This type of data is straightforward to analyze using traditional tools because of its predefined schema.
Unstructured Data, on the other hand, is free-form and lacks a predefined format. Think of:
- Text documents and emails.
- Social media posts.
- Videos and images.
While unstructured data is rich in potential insights, it requires advanced tools like natural language processing (NLP) and machine learning to unlock its value.
From Data to Information: A Shift in Meaning
When we transition from data to information, the definitions of structured and unstructured undergo a fascinating flip.
Structured Information is presented in a clear, organized manner, often contextualized to deliver meaning. Examples include:
- Business reports summarizing key metrics.
- News articles explaining a story.
- Presentations with a logical flow of ideas.
Unstructured Information, however, refers to raw data that lacks organization or context. For instance:
- A database may hold structured data but appear unstructured as information if it lacks narrative or context.
- A text document, while unstructured data, can become structured information if it’s well-organized and provides meaning.
This paradox highlights how the lens through which we view data changes its perceived structure. The same dataset can shift from structured to unstructured depending on its use and the tools applied.
The Role of Context in Structure
The core of the paradox lies in context:
- Structured Data: Inherently organized, context-independent.
- Structured Information: Derives its structure from how it’s contextualized and presented.
For example, a spreadsheet of sales data is structured data. But without interpretation or visualization, it might be considered unstructured information. Conversely, a narrative report summarizing trends from that spreadsheet transforms raw numbers into structured information.
AI: Bridging the Structure Divide
Artificial intelligence is revolutionizing how we approach the paradox of structured and unstructured data and information. Techniques like Retrieval-Augmented Generation (RAG) and Natural Language Processing (NLP) demonstrate how AI adds structure, context, and usability to raw data.
Retrieval-Augmented Generation (RAG)
RAG combines retrieval-based systems with generative models. It retrieves relevant data from a knowledge base and uses it to generate meaningful, contextualized outputs. This is particularly powerful for handling unstructured data, as it dynamically adds context and structure. For instance, unstructured social media posts can be transformed into structured insights for sentiment analysis.
Natural Language Processing (NLP)
NLP enables machines to process and understand human language, making it essential for extracting insights from unstructured data like text documents and emails. Tasks like sentiment analysis, entity recognition, and summarization transform raw data into actionable information. NLP exemplifies the paradox: structured algorithms process unstructured data to produce structured outputs.
Deep Learning and Knowledge Representation
Architectures like Convolutional Neural Networks (CNNs) and Transformers rely on structured designs to process unstructured data such as images and text. Similarly, tools like knowledge graphs structure vast datasets into meaningful relations. These techniques highlight the interplay between structured systems and unstructured origins, emphasizing the evolving definitions of structure.
Integration and Big Data
Data lakes and federated learning demonstrate how unstructured data can coexist with structured formats, unlocking immense value. AI-powered tools process and integrate these diverse datasets, yet the context of their use often dictates whether the outputs are perceived as structured or unstructured information.
Practical Implications of the Paradox
Knowledge and Structural Capital
Knowledge and structural capital represent the intangible assets of an organization, where the paradox of structure plays a significant role. Structural capital, like organizational processes, databases, and intellectual property, thrives on structured formats to ensure reliability and scalability. However, knowledge capital—which resides in human expertise and informal communication—often exists in unstructured forms.
To surface knowledge effectively, organizations can:
- Leverage knowledge graphs to connect unstructured insights with structured datasets.
- Implement collaborative tools that capture informal knowledge while adding contextual metadata.
- Use AI-driven systems to extract, organize, and present tacit knowledge in actionable ways.
By bridging structured and unstructured formats, businesses can unlock the potential of their structural and knowledge capital to drive innovation and informed decision-making.
Authoritative Information and Records Management
Authoritative information, such as records in a management system, represents a unique challenge and opportunity in the structured-unstructured paradox. Records, represented by a diamond icon in the diagram, symbolize the most valuable pieces of information within an organization. Much like a diamond, records are rare, meticulously structured, and incredibly enduring. They carry immense value due to their role in preserving the integrity, traceability, and historical accuracy of information.
Records management systems surface authoritative information by using:
- Metadata: To add structure and context to unstructured records.
- Audit Trails: To ensure the integrity and traceability of information.
- AI Tools: To classify, organize, and extract insights from large volumes of unstructured records.
However, inheriting authoritative information, like records, when generating new content with AI can be incredibly challenging. AI systems often struggle to integrate and retain the structured integrity of records while creating content that is flexible and contextually rich. This difficulty arises from:
- Loss of Context: Records may lose their original narrative when deconstructed into smaller data points.
- Bias Introduction: Decisions about what parts of a record to prioritize or exclude can inadvertently distort meaning.
- Complexity of Traceability: Maintaining audit trails and metadata in AI-generated outputs can be difficult.
Despite these challenges, ensuring authoritative records are effectively incorporated into new AI-generated content is critical. These records provide a foundation of trust, reliability, and traceability, which are essential for compliance, informed decision-making, and preserving organizational knowledge. By integrating robust records management systems with AI tools, organizations can maintain both structure and meaning in their content creation processes.
Data Processing and Analysis
- Structured Data: Easily analyzed with traditional tools like SQL and Excel.
- Unstructured Data: Requires advanced AI and machine learning techniques.
Storage and Management
- Structured Data: Stored in relational databases with predefined schemas.
- Unstructured Data: Stored in data lakes or NoSQL databases for greater flexibility.
Use Cases
- Structured Data: Ideal for financial reporting, inventory management, and CRM systems.
- Unstructured Data: Powers sentiment analysis, image recognition, and social media monitoring.
Structured Data vs. Structured Information: A Philosophical Debate
Which has more structure: data or information? The answer depends on your perspective:
- Structured Data: Highly organized for computational efficiency.
- Structured Information: Organized for human understanding and decision-making.
While structured data excels in technical tasks, structured information adds layers of meaning and narrative that are essential for communication and strategy. This debate underscores the importance of context in defining structure.
How does bias play into this? When converting data into information, decisions are made about what to include, exclude, or highlight—often introducing bias. Similarly, how does this conversion alter meaning? Can the structure of data be preserved without losing nuance in the transition to information? These questions challenge us to think critically about the implications of structure in both technical and human-centered systems.
The Future of the Data Paradox
As AI evolves, the line between structured and unstructured will blur. AI tools will continue to transform raw, unstructured data into meaningful, structured information, making all data increasingly usable. This shift emphasizes the importance of context—not just for machines, but for humans too.
Conclusion
The paradox of structured and unstructured data and information underscores the critical role of context in data management. By leveraging AI and advanced tools, we can unlock the full potential of both structured and unstructured formats. Understanding this dynamic is key to navigating the data-rich world we live in today—and to transforming raw data into meaningful, actionable insights.